Step 1: Create a new project
1. From your preferred development directory, create a directory for a new project and cd into it:
mkdir graphql-server-example
cd graphql-server-example
2. Initialize a new Node.js project with npm (or another package manager you prefer, such as Yarn):
npm init --yes
npm pkg set type="module"
Step 2: Install dependencies
Applications that run Apollo Server require two top-level dependencies:
graphql (also known as graphql-js) is the library that implements the core GraphQL parsing and execution algorithms.
@apollo/server is the main library for Apollo Server itself. Apollo Server knows how to turn HTTP requests and responses into GraphQL operations and run them in an extensible context with support for plugins and other features.
Run the following command to install both of these packages and save them in your project's node_modules directory:
npm install @apollo/server graphql
Set up with JavaScript
If you are using JavaScript, create a index.js file that will contain all of the code for our example application:
touch index.js
Now replace the default scripts entry in your package.json file with these type and scripts entries:
pckage.json
{
// ...etc.
"type": "module",
"scripts": {
"start": "node index.js"
}
// other dependencies
}
Step 3: Define your GraphQL schema
Every GraphQL server (including Apollo Server) uses a schema to define the structure of data that clients can query. In this example, we'll create a server for querying a collection of books by title and author.
index.js
Open index.js in your preferred code editor and paste the following into it:
import { ApolloServer } from '@apollo/server';
import { startStandaloneServer } from '@apollo/server/standalone';
// A schema is a collection of type definitions (hence "typeDefs")
// that together define the "shape" of queries that are executed against
// your data.
const typeDefs = `#graphql
# Comments in GraphQL strings (such as this one) start with the hash (#) symbol.
# This "Book" type defines the queryable fields for every book in our data source.
type Book {
title: String
author: String
}
# The "Query" type is special: it lists all of the available queries that
# clients can execute, along with the return type for each. In this
# case, the "books" query returns an array of zero or more Books (defined above).
type Query {
books: [Book]
}
`;
Step 4: Define your data set
Now that we've defined the structure of our data, we can define the data itself.
Apollo Server can fetch data from any source you connect to (including a database, a REST API, a static object storage service, or even another GraphQL server). For the purposes of this tutorial, we'll hardcode our example data.
Add the following to the bottom of your index.ts file:
const books = [
{
title: 'The Awakening',
author: 'Kate Chopin',
},
{
title: 'City of Glass',
author: 'Paul Auster',
},
];
Step 5: Define a resolver
We've defined our data set, but Apollo Server doesn't know that it should use that data set when it's executing a query. To fix this, we create a resolver.
Resolvers tell Apollo Server how to fetch the data associated with a particular type. Because our Book array is hardcoded, the corresponding resolver is straightforward.
Add the following to the bottom of your index.js file:
// Resolvers define how to fetch the types defined in your schema.
// This resolver retrieves books from the "books" array above.
const resolvers = {
Query: {
books: () => books,
},
};
Step 6: Create an instance of ApolloServer
We've defined our schema, data set, and resolver. Now we need to provide this information to Apollo Server when we initialize it.
Add the following to the bottom of your index.js file:
// The ApolloServer constructor requires two parameters: your schema
// definition and your set of resolvers.
const server = new ApolloServer({
typeDefs,
resolvers,
});
// Passing an ApolloServer instance to the `startStandaloneServer` function:
// 1. creates an Express app
// 2. installs your ApolloServer instance as middleware
// 3. prepares your app to handle incoming requests
const { url } = await startStandaloneServer(server, {
listen: { port: 4000 },
});
console.log(`🚀 Server ready at: ${url}`);
Step 7: Start the server
We're ready to start our server! Run the following from your project's root directory:
npm start
You should now see the following output at the bottom of your terminal:
🚀 Server ready at: http://localhost:4000/
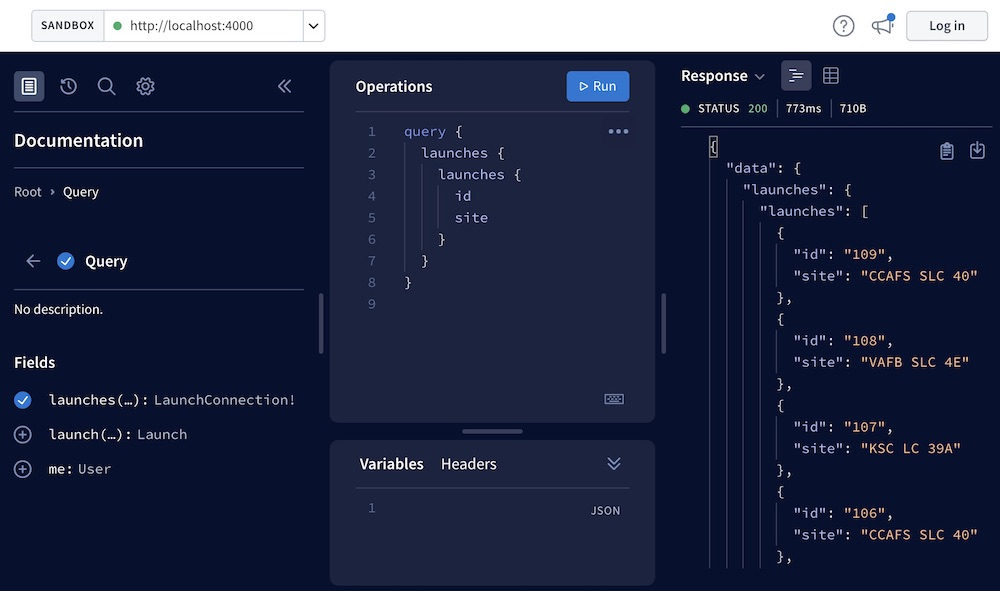
Step 8: Execute your first query
We can now execute GraphQL queries on our server. To execute our first query, we can use
Apollo Sandbox.
Visit http://localhost:4000 in your browser, which will open the Apollo Sandbox: